Predicting Titanic passenger survival using tidymodels
By Niels van der Velden in reticulate R Python Machine Learning
February 23, 2022
Titanic survival prediction using Tidymodels and the Tidyverse
In this notebook I use the
tidyverse package to predict passenger survival on the Titanic. I define some new features that were mostly based on the titanic-using-name-only
notebook from Chris Deotte. I then fit an xgboost model on the data to predict survival and tune the model in Python using the optuna package. The final model achieves a score of 0.811 which places it in the top 2%.
Required packages
#Load all libraries
#Load packages
library(tidyverse)
library(tidymodels)
library(xgboost)
library(reticulate)
Loading the data
I downloaded the test and train data from Kaggle. After loading of the data I added an extra “id” column such that the data can be easily separated again into “train” and “test” after the feature engineering.
train <- read.csv('train.csv')
test <- read.csv('test.csv')
#Replace empty strings "" with NA
test[test==""] <- NA
#Combind data
data_all = bind_rows(list("train" = train, "test" = test), .id = "id")
data_all[data_all==""] <- NA
glimpse(data_all)
## Rows: 1,309
## Columns: 13
## $ id <chr> "train", "train", "train", "train", "train", "train", "tra~
## $ PassengerId <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,~
## $ Survived <int> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1~
## $ Pclass <int> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, 2, 3, 2, 3, 3~
## $ Name <chr> "Braund, Mr. Owen Harris", "Cumings, Mrs. John Bradley (Fl~
## $ Sex <chr> "male", "female", "female", "female", "male", "male", "mal~
## $ Age <dbl> 22, 38, 26, 35, 35, NA, 54, 2, 27, 14, 4, 58, 20, 39, 14, ~
## $ SibSp <int> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, 0, 4, 0, 1, 0~
## $ Parch <int> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, 0, 1, 0, 0, 0~
## $ Ticket <chr> "A/5 21171", "PC 17599", "STON/O2. 3101282", "113803", "37~
## $ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4583, 51.8625,~
## $ Cabin <chr> NA, "C85", NA, "C123", NA, NA, "E46", NA, NA, NA, "G6", "C~
## $ Embarked <chr> "S", "C", "S", "S", "S", "Q", "S", "S", "S", "C", "S", "S"~
Feature engineering
The following features are added:
- Title: The title is extracted from the Name of each passenger and classified into “Man”, “Female” or “Boy”.
- FamilySize: Siblings/Spouses (SibSp) + Parents/Children (Parch) + 1.
- GroupID: First 4 digits of the Ticket + FarePrice.
- GroupSize: Count of each groupID.
- TicketFreq: How often a Ticket occurs.
- manGroupes_survived/died: Man is part of group of man traveling together who all survived/died.
- femaleGroupes_survived/died: Female is part of group of females traveling together who all survived/died.
- boyFemaleGroupes_survived/died: Boy is part of a group of boys/females traveling together who all survived/died.
###############feature Extraction
featureExtraction <- function(data){
#Fill Missing value for Embarked
data <-
data %>% mutate(
Embarked = case_when(
as.character(Ticket) == "113572" ~"S",
TRUE ~as.character(Embarked)
)
)
#Get Cabin Type
data <-
data %>%
mutate(
CabinType = substr(Cabin, start=1, stop=1)
) %>%
mutate(
CabinType = case_when(
CabinType == "" ~"Missing",
TRUE ~CabinType
)
)
#Remove special characters from Ticket
data <-
data %>%
mutate(
Ticket = str_replace_all(Ticket, "[[:punct:][:space:]]", "")
)
#Extract Title
data <-
data %>%
mutate(
#Look for first occurance of , followed by a space.
#Capture everything untill first occurance of ".".
Title = str_extract(Name, "(?<=,[:space:])(.*?)[.]"),
LastName = str_extract(Name, ".*(?=[,])")
)
#Adjusted Ticket Price
data <-
data %>%
group_by(Ticket) %>%
mutate(
TicketFreq = n(),
AdjFare = Fare / TicketFreq
) %>%
ungroup()
#Group titles
Man <- c("Mr.", "Sir.", "Don.", "Rev.", "Major.",
"Col.", "Capt.", "Jonkheer.",
"Dr.", "Nobel.")
Female <- c("Mrs.", "Miss.", "Mme.", "Ms.", "Lady.", "Mlle.", "the Countess.", "Dona.")
Boy <- c("Master.")
data <-
data %>%
rowwise() %>%
mutate(
Title =
case_when(
(Title %in% Man) ~"Man",
(Title %in% Female) ~"Female",
(Title %in% Boy) ~"Boy",
TRUE ~Title
)
)
#FamilySize
data <-
data %>%
mutate(
familySize = as.numeric(SibSp) + as.numeric(Parch) + 1
)
data <-
data %>%
mutate(
familySize =
case_when(
familySize <= 3 ~"Small",
between(familySize, 4, 6) ~"Medium",
familySize >= 7 ~"Large"
)
)
#GroupID
data <-
data %>%
mutate(
groupID = paste(substr(as.character(Ticket), 1, 4), AdjFare)
)
data <-
data %>%
mutate(
groupID = str_replace_all(groupID, "[[:punct:][:space:]]", "")
)
#GroupSize
data <-
data %>%
group_by(groupID) %>%
mutate(
groupSize = n()
)
#Man Groups
manGroups <-
data %>%
filter(Sex == "male") %>%
group_by(groupID) %>%
filter(n() >= 2) %>%
mutate(equal = n_distinct(Survived, na.rm = TRUE)) %>%
filter(equal == 1)
manGroups_survived <- manGroups %>% filter(Survived == 1)
manGroups_died <- manGroups %>% filter(Survived == 0)
#Female Groups
femaleGroups <-
data %>%
filter(Sex == "female") %>%
group_by(groupID) %>%
filter(n() >= 2) %>%
mutate(equal = n_distinct(Survived, na.rm = TRUE)) %>%
filter(equal == 1)
femaleGroups_survived <- femaleGroups %>% filter(Survived == 1)
femaleGroups_died <- femaleGroups %>% filter(Survived == 0)
#boyFemale Groups
boyFemaleGroups <-
data %>%
filter(Title != "Man") %>%
group_by(groupID) %>%
filter(n() >= 2) %>%
mutate(
equal = n_distinct(Survived, na.rm = TRUE),
mixed = n_distinct(Title)) %>%
filter(equal == 1 && mixed == 2)
boyFemaleGroups_survived <- boyFemaleGroups %>% filter(Survived == 1)
boyFemaleGroups_died <- boyFemaleGroups %>% filter(Survived == 0)
data <-
data %>%
rowwise() %>%
mutate(
manGroup_survived =
case_when(
(groupID %in% manGroups_survived$groupID && Sex == "male") ~1,
TRUE~0
),
manGroup_died =
case_when(
(groupID %in% manGroups_died$groupID && Sex == "male") ~1,
TRUE~0
),
femaleGroup_survived =
case_when(
(groupID %in% femaleGroups_survived$groupID && Sex == "female") ~1,
TRUE~0
),
femaleGroup_died =
case_when(
(groupID %in% femaleGroups_died$groupID && Sex == "female") ~1,
TRUE~0
),
boyFemaleGroups_survived =
case_when(
(groupID %in% boyFemaleGroups_survived$groupID && Title == "Boy") ~1,
TRUE~0
),
boyFemaleGroups_died =
case_when(
(groupID %in% boyFemaleGroups_died$groupID && Title == "Boy") ~1,
TRUE~0
)
)
#Convert to factors
data <-
data %>%
mutate(
across(where(is_character),as_factor),
across(where(is_integer),as_factor)
)
return(data)
}
data_processed <- featureExtraction(data_all)
glimpse(data_processed)
## Rows: 1,309
## Columns: 27
## Rowwise: groupID
## $ id <fct> train, train, train, train, train, train, tra~
## $ PassengerId <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14~
## $ Survived <fct> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, ~
## $ Pclass <fct> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, ~
## $ Name <fct> "Braund, Mr. Owen Harris", "Cumings, Mrs. Joh~
## $ Sex <fct> male, female, female, female, male, male, mal~
## $ Age <dbl> 22, 38, 26, 35, 35, NA, 54, 2, 27, 14, 4, 58,~
## $ SibSp <fct> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, ~
## $ Parch <fct> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, ~
## $ Ticket <fct> A521171, PC17599, STONO23101282, 113803, 3734~
## $ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4~
## $ Cabin <fct> NA, C85, NA, C123, NA, NA, E46, NA, NA, NA, G~
## $ Embarked <fct> S, C, S, S, S, Q, S, S, S, C, S, S, S, S, S, ~
## $ CabinType <fct> NA, C, NA, C, NA, NA, E, NA, NA, NA, G, C, NA~
## $ Title <fct> Man, Female, Female, Female, Man, Man, Man, B~
## $ LastName <fct> Braund, Cumings, Heikkinen, Futrelle, Allen, ~
## $ TicketFreq <fct> 1, 2, 1, 2, 1, 1, 2, 5, 3, 2, 3, 1, 1, 7, 1, ~
## $ AdjFare <dbl> 7.250000, 35.641650, 7.925000, 26.550000, 8.0~
## $ familySize <fct> Small, Small, Small, Small, Small, Small, Sma~
## $ groupID <chr> "A521725", "PC173564165", "STON7925", "113826~
## $ groupSize <fct> 5, 2, 18, 6, 1, 1, 4, 5, 3, 2, 3, 9, 2, 7, 8,~
## $ manGroup_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ manGroup_died <dbl> 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, ~
## $ femaleGroup_survived <dbl> 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, ~
## $ femaleGroup_died <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, ~
## $ boyFemaleGroups_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ boyFemaleGroups_died <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
Data splitting
The train data is extract from the processed data using the “id” column. The data is then split using the initial_split() function which splits the data into a training set and testing set which can be accesed using the training() or testing() function.
set.seed(123) # For reproducible results
train <-
data_processed %>%
filter(id == "train") %>%
mutate(
Survived = as.factor(Survived)
) %>% select(-id)
data_split <- initial_split(train)
data_train <- training(data_split)
data_test <- testing(data_split)
Model
In this step the model is defined. I choose to use “xgboost” but this can be easilly changed to a randomForest or any other ML model.
#check data after prep
xg_model <-
boost_tree(
) %>%
set_engine("xgboost", eval_metric='logloss') %>%
set_mode("classification")
Recipe
In this step a recipe is defined to pre-process the data. I have chosen to load all data first and then define the predictors using the update_role() function. This allows me to quickly play around using different sets of predictors. step_impute_knn() is used to impute missing values using k-nearest-neighbors. step_novel() is used to assign a previously unseen factor level to a new value. This prevents errors from occurring when values are present in the training data but not in the test data. step_dummy() is used to convert nominal data (e.g. male, female) into one or more numeric binary model terms (e.g. 0, 1) which is required for some ML models.
pred_vars <- c("manGroup_survived", "manGroup_died", "boyFemaleGroups_survived", "femaleGroup_died", "femaleGroup_survived", "boyFemaleGroups_died",
"Sex","TicketFreq","groupSize","familySize")
#Recipe
xg_recipe <-
recipe(Survived ~., data=data_split) %>%
step_impute_knn(Age, AdjFare, Cabin, CabinType, impute_with = imp_vars(Pclass, groupSize)) %>%
step_novel(groupID, Ticket) %>%
step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
update_role(all_predictors(), old_role = "predictor", new_role = "other") %>%
update_role(all_of(pred_vars), old_role = "other", new_role = "predictor")
#Check data
prep <- prep(xg_recipe)
prep_data <-
bake(prep, new_data = train)
glimpse(prep_data)
## Rows: 891
## Columns: 53
## Rowwise: groupID
## $ PassengerId <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14~
## $ Pclass <fct> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, ~
## $ Name <fct> "Braund, Mr. Owen Harris", "Cumings, Mrs. Joh~
## $ Age <dbl> 22.0, 38.0, 26.0, 35.0, 35.0, 23.6, 54.0, 2.0~
## $ SibSp <fct> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, ~
## $ Parch <fct> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, ~
## $ Ticket <fct> A521171, PC17599, STONO23101282, 113803, 3734~
## $ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4~
## $ Cabin <fct> F G63, C85, G6, C123, D6, C111, E46, F G73, G~
## $ Embarked <fct> S, C, S, S, S, Q, S, S, S, C, S, S, S, S, S, ~
## $ CabinType <fct> F, C, G, C, C, C, E, F, F, F, G, C, G, G, G, ~
## $ Title <fct> Man, Female, Female, Female, Man, Man, Man, B~
## $ LastName <fct> Braund, Cumings, Heikkinen, Futrelle, Allen, ~
## $ AdjFare <dbl> 7.250000, 35.641650, 7.925000, 26.550000, 8.0~
## $ groupID <fct> A521725, PC173564165, STON7925, 11382655, 373~
## $ manGroup_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ manGroup_died <dbl> 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, ~
## $ femaleGroup_survived <dbl> 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, ~
## $ femaleGroup_died <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, ~
## $ boyFemaleGroups_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ boyFemaleGroups_died <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ Survived <fct> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, ~
## $ Sex_male <dbl> 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, ~
## $ Sex_female <dbl> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, ~
## $ TicketFreq_X1 <dbl> 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, ~
## $ TicketFreq_X2 <dbl> 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, ~
## $ TicketFreq_X5 <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ TicketFreq_X3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, ~
## $ TicketFreq_X7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, ~
## $ TicketFreq_X6 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ TicketFreq_X4 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ TicketFreq_X8 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ TicketFreq_X11 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ familySize_Small <dbl> 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, ~
## $ familySize_Medium <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ familySize_Large <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, ~
## $ groupSize_X5 <dbl> 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X2 <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, ~
## $ groupSize_X18 <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X6 <dbl> 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X1 <dbl> 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X4 <dbl> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, ~
## $ groupSize_X9 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, ~
## $ groupSize_X7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, ~
## $ groupSize_X8 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, ~
## $ groupSize_X10 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X49 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X13 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X12 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X17 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X11 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ groupSize_X19 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
Workflow
In this step we combine the recipe with the model into a workflow.
#Workflow
xg_workflow <-
workflow() %>%
add_recipe(xg_recipe) %>%
add_model(xg_model)
Model validation
First, I test accuracy using the data_split where 3/4 of the data is used for training and 1/3 for testing. Next, I test accuracy using cross validation by resampling the data into 10 groups of roughly the same size.
xg_fit <-
xg_workflow %>%
last_fit(data_split)
#Accuracy on test data
accuracy <- xg_fit %>% collect_metrics()
accuracy
## # A tibble: 2 x 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy binary 0.874 Preprocessor1_Model1
## 2 roc_auc binary 0.946 Preprocessor1_Model1
set.seed(123)
#Accuracy on cross Validation
folds <- vfold_cv(train)
xg_fit_rs <-
xg_workflow %>%
fit_resamples(folds)
accuracy_xg <- xg_fit_rs %>% collect_metrics()
accuracy_xg
## # A tibble: 2 x 6
## .metric .estimator mean n std_err .config
## <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 accuracy binary 0.880 10 0.00919 Preprocessor1_Model1
## 2 roc_auc binary 0.940 10 0.00562 Preprocessor1_Model1
Model tuning
The model achieved an accuracy of 0.88 which is already very good. To optimize the model further I tune the model in Python using the optuna package (see my
previous post).
tune_r_model <- function(trees = 1000, tree_depth = NULL, min_n = NULL, loss_reduction = NULL, sample_size = NULL, mtry = NULL, learn_rate = NULL){
set.seed(123)
xg_model <-
boost_tree(
trees = !!trees,
tree_depth = !!tree_depth,
min_n = !!min_n,
loss_reduction = !!loss_reduction,
sample_size = !!sample_size,
mtry = !!mtry,
learn_rate = !!learn_rate
) %>%
set_engine("xgboost", eval_metric='logloss') %>%
set_mode("classification")
#Recipe
pred_vars <- c("manGroup_survived", "manGroup_died", "boyFemaleGroups_survived", "femaleGroup_died", "femaleGroup_survived", "boyFemaleGroups_died",
"Sex","TicketFreq","groupSize","familySize")
#Recipe
xg_recipe <-
recipe(Survived ~., data=data_split) %>%
step_impute_knn(Age, AdjFare, Cabin, CabinType, impute_with = imp_vars(Pclass, groupSize)) %>%
step_novel(groupID, Ticket) %>%
step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
update_role(all_predictors(), old_role = "predictor", new_role = "other") %>%
update_role(all_of(pred_vars), old_role = "other", new_role = "predictor")
#Workflow
xg_workflow <-
workflow() %>%
add_recipe(xg_recipe) %>%
add_model(xg_model)
xg_fit_rs <-
xg_workflow %>%
fit_resamples(folds)
accuracy_xg <- xg_fit_rs %>% collect_metrics()
return(accuracy_xg$mean[1])
}
## The best found Accuracy = 0.883
## With Parameters: {'tree_depth': 13, 'min_n': 2, 'loss_reduction': 0.022125898017580893, 'sample_size': 0.9736252720006023, 'mtry': 2, 'learn_rate': 0.08375865362374317}
Fit tuned model on test data
After tuning the accuracy is 0.883 which is a slight improvement over 0.88. The tuned model is fitted using the processed training data and Survival is predicted on the test data.
#Best parameters found by optuna
best_params <- as_tibble(py$best_params)
set.seed(123)
final_xgb <- finalize_workflow(
xg_workflow,
best_params
)
fit_tuned_model <- fit(final_xgb, data = train)
#Prepare predict data
predict_processed <-
data_processed %>%
filter(id == "test") %>%
select(-id, -Survived)
glimpse(predict_processed)
## Rows: 418
## Columns: 25
## Rowwise: groupID
## $ PassengerId <fct> 892, 893, 894, 895, 896, 897, 898, 899, 900, ~
## $ Pclass <fct> 3, 3, 2, 3, 3, 3, 3, 2, 3, 3, 3, 1, 1, 2, 1, ~
## $ Name <fct> "Kelly, Mr. James", "Wilkes, Mrs. James (Elle~
## $ Sex <fct> male, female, male, male, female, male, femal~
## $ Age <dbl> 34.5, 47.0, 62.0, 27.0, 22.0, 14.0, 30.0, 26.~
## $ SibSp <fct> 0, 1, 0, 0, 1, 0, 0, 1, 0, 2, 0, 0, 1, 1, 1, ~
## $ Parch <fct> 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ Ticket <fct> 330911, 363272, 240276, 315154, 3101298, 7538~
## $ Fare <dbl> 7.8292, 7.0000, 9.6875, 8.6625, 12.2875, 9.22~
## $ Cabin <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N~
## $ Embarked <fct> Q, S, Q, S, S, S, Q, S, C, S, S, S, S, S, S, ~
## $ CabinType <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N~
## $ Title <fct> Man, Female, Man, Man, Female, Man, Female, M~
## $ LastName <fct> Kelly, Wilkes, Myles, Wirz, Hirvonen, Svensso~
## $ TicketFreq <fct> 1, 1, 1, 1, 2, 1, 1, 3, 1, 3, 1, 1, 2, 2, 2, ~
## $ AdjFare <dbl> 7.829200, 7.000000, 9.687500, 8.662500, 6.143~
## $ familySize <fct> Small, Small, Small, Small, Small, Small, Sma~
## $ groupID <chr> "330978292", "36327", "240296875", "315186625~
## $ groupSize <fct> 3, 1, 1, 3, 2, 1, 2, 3, 1, 4, 49, 1, 2, 2, 2,~
## $ manGroup_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, ~
## $ manGroup_died <dbl> 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ~
## $ femaleGroup_survived <dbl> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ femaleGroup_died <dbl> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ boyFemaleGroups_survived <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
## $ boyFemaleGroups_died <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
##Prepare data for submission
predict_fit <-
fit_tuned_model %>%
predict(new_data = predict_processed) %>%
bind_cols(predict_processed) %>%
select(PassengerId, Survived = .pred_class)
glimpse(predict_fit)
## Rows: 418
## Columns: 2
## $ PassengerId <fct> 892, 893, 894, 895, 896, 897, 898, 899, 900, 901, 902, 903~
## $ Survived <fct> 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1~
#Write to .csv
write.csv(predict_fit, file = "titanic_submission.csv", row.names = FALSE)
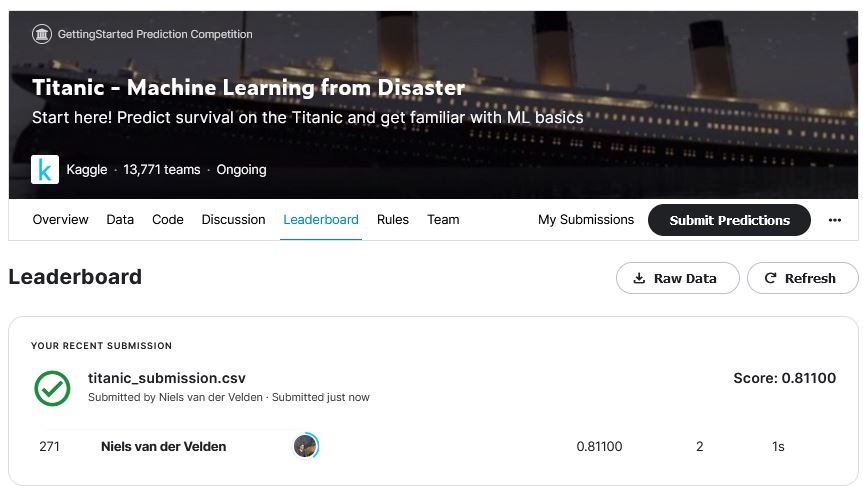
Final Score
The final model reached a score of 0.811 on Kaggle and a ranking of 271. I think this is pretty good considering there are 13k submissions. Also, it is easy to find out if a passenger survived the Titanic disaster using a quick Google search. I suspect that many of the higher scoring models use that information to boost there score.